以下是刚刚完成的一个作业,后半部分图文互换太麻烦了,我都贴了图,会有一些不齐,凑合看吧,3个实验的代码比较长,欢迎来信索取文档和3份代码,我的email:mgigabyte[艾特]gmail.com
可能会有部分网友感觉很垃圾,很无聊,权且仅当是一个作业吧,我对这个作业的预算是3天,实际1天半完成,还是比较满意的。
字典序全排列生成算法提速
摘 要: 本文实验了字典序全排列生成算法,并给出了三种优化方法,采用t假设检验的方法证明3种优化方法都可接受,最终的优化方法比作为baseline的算法提速了29.7倍。
关键词:字典序全排列生成算法;t假设检验。
1 引言
在全排列生成方法是一种将n个不同的项按照一定的顺序,无重复、无遗漏地列举出全部的不同的排列方法,n个不同项将会生成n阶层个不同的排列方案,在这些方法中字典序方法最为自然容易理解,但字典序法不可避免地需要循环或者递归,而以邻位对换法等为代表的LOOPLESS的方法避免了循环和递归,但由于每次执行都需要依赖此前的结果,因此在分布式,多核环境下显得性能不高。字典序方法虽然依赖循环和递归但其很容易将任务分解在不同的计算单元在多核,甚至是分布式的环境下,可以获得很好的性能。本文从字典序的3重优化过程,来探讨字典序的性能提速。
2 相关工作
论文[1]提到了常见的通过邻位对换法来获得全排列生成算法,论文[2]讨论了并行计算排列生成算法,并且支持scalability,性能和计算机CPU核数量相关,论文[3]提出了一种新的计算第kth个排列方案的并行算法。
3 系统的优化方法
本文利用字典序的基本算法,生成一个最简单的算法作为性能比较的baseline。之后采用了递归底部消除,多线程,文件读写优化等方法,将性能提升29.7倍。
以[1,2,3,4]为例进行举例:
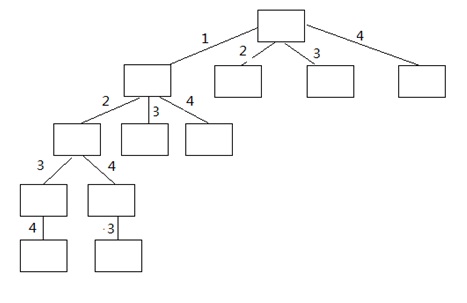
图1 递归过程
递归过程为一个从k叉树逐级递减,直到1叉树,深入优先的过程,栈的深度为O(n),n为给出的n不同项的数目。
第一个优化的想法:在递归到某个k叉树的节点时,没有必要继续递归,而是可以直接求解,从而消除底部的递归,实验尝试了消除底部1层的递归,消除2层的递归和消除3层的递归,实验表明消除2层的递归的性能更加优良,性能提升3%,并以此为基础继续进行优化。
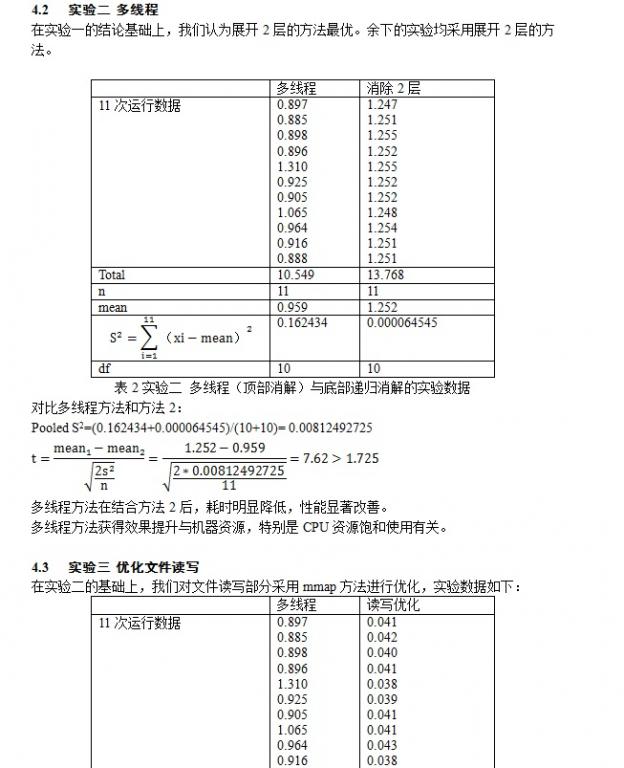
第二个优化的想法:整个计算都是顺序执行,系统的其他CPU核并没有使用上,使用并行计算的方法对计算资源进行饱和。和第一种优化思路相反,本文使用了在递归树的顶部进行展开出9个线程分别计算,实验表明采用这种方法,性能提升31%,如图2所示。
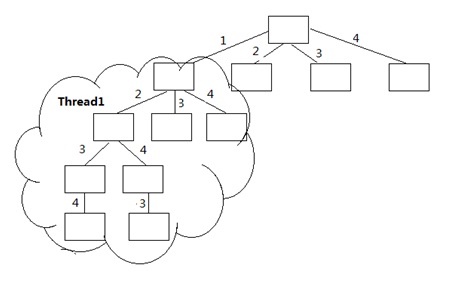
图2 多线程方法等价于在顶部展开
如图2所示,1打头的字典序算法由一个独立的线程完成,并写入一个独立的文件f1。因此4个元素的情况下,结果会生成4个文件,最后用cat命令将这4个文件进行合并输出。如果将结果输出文件看成一个织布,那么这里同时让4个织布工人同时织布,每个织布工人都从头开始织布,不考虑其他织布工人的情况,最后把各自的织布合并成为一个完成的布匹。
第三个优化方法是:从结果文件的角度考虑系统同时有10个线程在进行磁盘IO,最后还需要进行一次合并,如果采用mmap将文件映射到内存,直接在内存中写入,最后一次性sync进磁盘,可以大大提高效率。实验表明采用这种方法后,性能提升2183%。只所以能高效优化,可以认为4个织布工人在同一张大布上分别织布,织完后就是最后的结果,不同的工人织布的起始点不同,各自安排好织布的起始点分别织布。性能的提升主要和mmap这种文件读写加速有关。
使用最优的优化算法后,我们对9个不同的项做了实验,在最好的算法下,9阶层个输出项只需要平均0.042秒即可完成,相当于输出一个项只需0.12微秒。
4 实验和分析
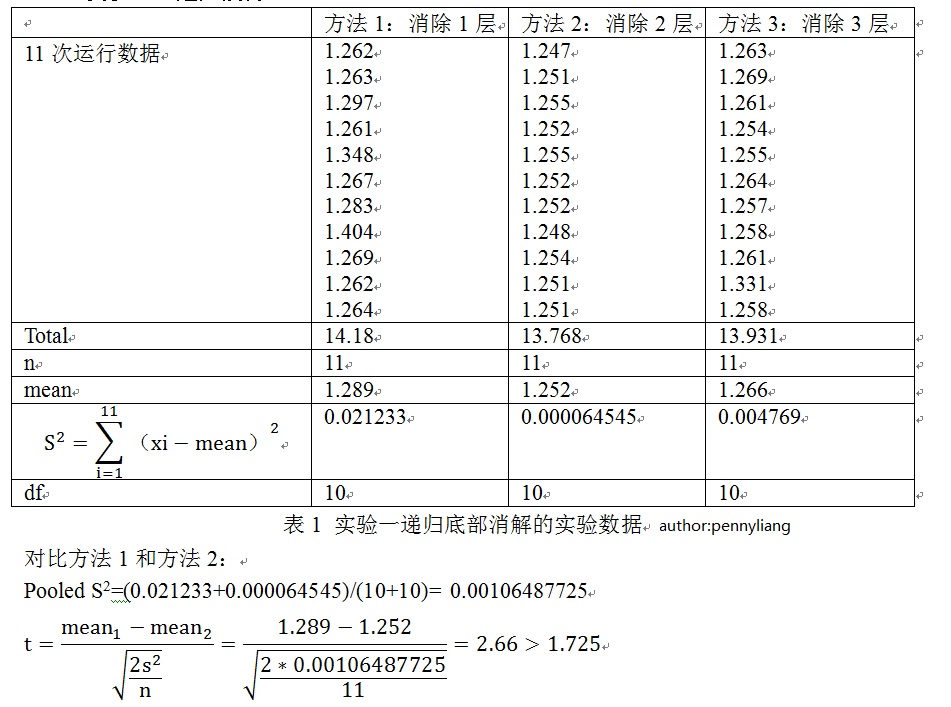
首先我们使用了递归底部展开的优化方法,该优化方法与快速排序在递归到最后k个元素后采用简单的直接插入排序类似,以下是实验一的数据,我们采用t检验的假设检验的方法,这种方法可以有效地估计性能提升是否可以接受。用t检验来对3种展开的方法进行效果估计,并在最后给出了产生这些数据的分析。
实验结论,方法2比方法1和方法3都具有显著的性能提升,方法2的有效性可以接受。
4.1 实验一 递归展开


分享到:





相关推荐
全排列生成算法中的字典序法的vc++源码
N个数字的字典序全排列,自己的小作业,参考dfs写的,
使用递归 :-------------输入给出正整数n,输出1到n的全排列,排列的输出顺序为字典序,每种排列占一行,数字间无空格,
利用中介数实现全排列算法,采用java实现。
这是组合数学的全排列生成算法,用C语言实现的,包括四种常见的全排列生成算法,字典序法,循环左移,循环右移,邻位对换的方法。
word版全排列生成算法,还有代码的。 字典序法 递增进位数制法 递减进位数制法 邻位交换法 n进位制法 递归类算法
清华大学选修组合数学的同学,不要抄袭此代码,会重复的!咱俩都没分!
字典序、邻位对换、递增进位制数,递减进位制数以及两种递归算法的C++实现,包含代码和exe文件,供大家参考!
字典序法生成全排列,希望对学习组合数学的同学有帮助
给出了字典排序求取全排列的算法实现,JAVA
全排列的几种不同算法,方便快捷的实现求全排列。思路简单清晰
排列生成算法 字典序法 C语言源代码 排列生成算法的一种,采用交换和逆序的方法生成排列
算法课写的小程序,在字典序下对输出序列的全排列
全排列算法有两个比较常见的实现:递归排列和字典序排列。 (1)递归实现 从集合中依次选出每一个元素,作为排列的第一个元素,然后对剩余的元素进行全排列,如此递归处理,从而得到所有元素的全排列。 (2)字典...
组合数学全排列字典序法组合数学全排列字典序法组合数学全排列字典序法组合数学全排列字典序法组合数学全排列字典序法组合数学全排列字典序法组合数学全排列字典序法组合数学全排列字典序法
字典序、邻位对换、递归递增进位制数法、递归的递减进位制数法生成全排列。除递归地增是O(n·n!)外,其余三个都是O(n!)。main函数是计算1——12生成全排列的运行时间。
问题描述:n个元素{1,2,3...n}有n!个不同的排列。将这n!个排列按字典序排列,并编号为0,1,...,n!...算法设计:给定n及n个元素{1,2,...}的一个排列,计算出这个排列的字典序值,以及按字典序排列的下一个排列。
字典序 基于C实现的按照字典序生成排列的算法,
用vc++实现的字典序算法的实现 很多功能正在添加完善之中
本题对于给定的 n 以及 n 个元素 {1, 2, ..., n } 的一个排列, 计算这个排列的字典序值, 以及按字典序排列的下一个排列. Input 有多个测试用例. 每个测试用例由两行组成, 第一行是一个自然数 n(n ≤ 20), 第二行...