k平均聚类发明于1956年, 该算法最常见的形式是采用被称为劳埃德算法(Lloyd algorithm)的迭代式改进探索法。劳埃德算法首先把输入点分成k个初始化分组,可以是随机的或者使用一些启发式数据。然后计算每组的中心点,根据中心点的位置把对象分到离它最近的中心,重新确定分组。继续重复不断地计算中心并重新分组,直到收敛,即对象不再改变分组(中心点位置不再改变)。 劳埃德算法和k平均通常是紧密联系的,但是在实际应用中,劳埃德算法是解决k平均问题的启发式法则,对于某些起始点和重心的组合,劳埃德算法可能实际上收敛于错误的结果。(上面函数中存在的不同的最优解) 虽然存在变异,但是劳埃德算法仍旧保持流行,因为它在实际中收敛非常快。实际上,观察发现迭代次数远远少于点的数量。然而最近,David Arthur和Sergei Vassilvitskii提出存在特定的点集使得k平均算法花费超多项式时间达到收敛。 近似的k平均算法已经被设计用于原始数据子集的计算。 从算法的表现上来说,它并不保证一定得到全局最优解,最终解的质量很大程度上取决于初始化的分组。由于该算法的速度很快,因此常用的一种方法是多次运行k平均算法,选择最优解。 k平均算法的一个缺点是,分组的数目k是一个输入参数,不合适的k可能返回较差的结果。另外,算法还假设均方误差是计算群组分散度的最佳参数。
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
typedef struct point{
double x;//x坐标
double y;//y坐标
int n;//属于哪个簇
char label[10];//点标号
}Point;
int main(){
int n;
int i, j, k = 0, l = 0;
int m;//点的个数
double sq;
double min = 65535;//存储最小的点距离
int pos;//标记最小点集
char c;
Point *center;//存储中心点
Point *pot;//存储坐标点
double *dis;//存储距离的
printf("输入中心点的个数:\n");
scanf("%d", &n);
getchar();
for(i = 0; i < n; i++){//分配空间
center = calloc(n, sizeof(struct point));
dis = calloc(n, sizeof(double));
if(center == NULL || dis == NULL){
printf("calloc() error\n");
exit(1);
}
}
for(i = 0; i < n; i++){
printf("输入第%d个中心点的坐标,usage:a1 (4.2,5.3)\n", (i + 1));
scanf("%s (%lf,%lf)", &(center[i].label), &(center[i].x), &(center[i].y));
getchar();
}
for(i = 0; i < n; i++){
printf("%s(%.2f,%.2f)\n", center[i].label, center[i].x, center[i].y);
}
printf("请输入一共有几个点:\n");
scanf("%d", &m);
getchar();
for(i = 0; i < m; i++){//分配空间
pot = calloc(m, sizeof(struct point));
if(pot == NULL){
printf("error\n");
exit(1);
}
}
for(i = 0; i < m; i++){
printf("请输入第%d个点的坐标usage:a1 (4.2,5.3)\n", i+1);
scanf("%s (%lf,%lf)", &pot[i].label, &pot[i].x, &pot[i].y);
getchar();
}
for(i = 0; i < m; i++){
printf("%s(%.2f,%.2f)\n", pot[i].label, pot[i].x, pot[i].y);
}
while(k < 3){//迭代3次
printf("第%d次迭代\n", k+1);
for(i = 0; i < m; i++){
min = 65535;
printf("%s", pot[i].label);
for(j = 0; j < n; j++){
dis[j] = sqrt(pow((pot[i].x - center[j].x), 2) + pow((pot[i].y - center[j].y), 2));
//printf("点(%.2lf,%.2lf)距离中心点为(%.2lf,%.2lf)的距离为%.3lf\n", pot[i].x, pot[i].y, center[j].x, center[j].y, dis[j]);
printf(" 和%s相距%.3lf", center[j].label, dis[j]);
if(min > dis[j]){
min = dis[j];
pos = j;
pot[i].n = j;//存储他的分类
}
}
printf("\n");
}
//计算新的中心点
for(i = 0; i < n; i++){//清空原先的中心点的值
center[i].x = 0;
center[i].y = 0;
center[i].n = 0;
}
for(i = 0; i < m; i++){
center[pot[i].n].x += pot[i].x;
center[pot[i].n].y += pot[i].y;
center[pot[i].n].n++;//记下有几个属于自己的点
}
for(i = 0; i < n; i++, l = 0){
printf("\n%s集的元素:(", center[i].label);
for(j = 0; j < m; j++){
if(i == pot[j].n){
printf("%s", pot[j].label);
l++;
if(center[i].n > l){
printf(", ");
}
}
}//end for
printf(")");
}
printf("\n");
for(i = 0; i < n; i++){
center[i].x = center[i].x/center[i].n;
center[i].y = center[i].y/center[i].n;
}
k++;
getchar();
}
return 0;
}
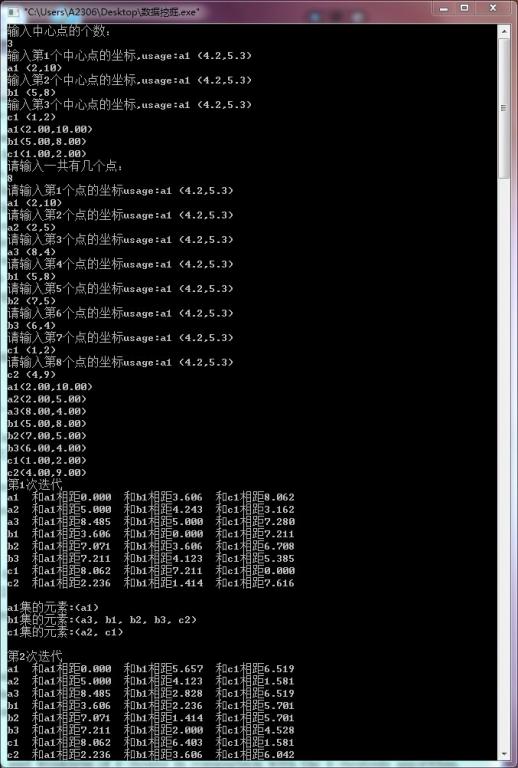
运行结果为
:

分享到:





相关推荐
数据挖掘 k-mean 实验 K-mean K-mean算法 K-means 数据挖掘 武汉理工
关于k-means算法的源程序代码.%%%%%%函数说明%%%%%% %输入: % sample--样本集; % k--聚类数目; %输出: % y--类标; % cnew--聚类中心; % n--迭代次数; function [y cnew n]=k_means(sample,k)
基于划分的数据挖掘K-means聚类算法分析.pdf
数据挖掘,K-means源码,数据集为iris-Data mining, K-means source code for the iris data set
在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
数据挖掘k-means k-medoids python代码实现 含测试数据
主要介绍了详解Java实现的k-means聚类算法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
这是k-means的MATLAB程序,主要用于各种数据的聚类等情况
使用java实现简单k-means聚类,描述空间点的归类
这是我用C语言编写的数据挖掘里面的一个K-Means算法,里面有截图。
数据挖掘K-Means算法在实践应用中的分析.pdf
用动画效果 帮助新手理解K-means聚类,有数据,有动画
使用C语言对传统K-means聚类算法进行了实现,内含较多注释。
K均值及其改进算法。原理比较简单,实现也是很容易,收敛速度快。当结果簇是密集的,而簇与簇之间区别明显时
K-means算法的MATLAB应用,利用K-means聚类原理,随机产生二维数据,将数据分成两类.
基于Matlab实现: 模式识别 K-Means算法 实现模式分类 模式识别 K-均值算法 实现模式分类
数据挖掘-K-Means聚类-算法原理.pdf
用c语言实现的k-means算法 本例子是用k-means算法来处理一些有关基因的数据,对上千个八维向量进行聚类分组
k-means算法的简单实现,可供大家下载学习。如果有什么问题,也可相互讨论
k-means实战,包括一个具体的例子。非常适合初级学习k-means聚类算法的人群